word2vec 是从大量文本数据中快速学习高质量的分布式词向量表示的一种方法。原始论文是 Efficient Estimation of Word Representations in Vector Space [pdf],进一步的优化策略见 Distributed Representations ofWords and Phrases and their Compositionality [pdf]。
在 tensorflow 的官方网站和github库,可以找到 word2vec 的代码实现,包括简化版、进阶版和讲解。本文基于上述示例代码,对 word2vec 的原理进行学习和理解。
实验环境:Windows 7 / Python 3.6.1 / Tensorflow 1.0.1 / Numpy 1.12.1+mkl
Step 0:安装所需的工具包
先安装 numpy 和 tensorflow。对于 Windows 用户,最省事的做法是在这里下载现成的 whl,然后 pip 安装。
手动安装 numpy 和 scipy 的时候可能遇到 no lapack/blas resources found 的错误,解决方案是使用上述网页提供的 numpy+mkl 工具。
注意 tensorflow 官方目前只提供适配 Python 3.5 版本的安装程序,但是同样可以在上述网页找到针对 Python 3.6 的非官方版 tensorflow,亲测可用。
另外,为了最后一步数据可视化,需要安装 sklearn 和 matplotlib。直接用 pip install 即可。
Step 1 & 2:下载数据与构造字典
下载一份一千七百万词的文本文件 text8.zip,并读取到一个字符串的列表 vocabulary。该文本的第一句话是 anarchism originated as a term of abuse first used against early working class radicals … 当然,也可以选择使用自己的语料。
利用 Counter 进行词频统计,保留出现频次最高的 50000 个词(其实是 49999 个),将其他非高频词全都替换为UNK。
构造字典 dictionary 和 reverse_dictionary,前者将词转化为自然数索引,后者反过来通过自然数索引查找到原本的词。
利用 dictionary 将语料从单词(字符串)的列表,转化为索引(自然数)的列表。
Step 3:生成训练数据
在word2vec中,有两种基本模型(算法):
- SG (skip-gram),已知中心词(center word),预测上下文窗口中有哪些词(context word);
- CBOW (continuous bag of words,连续词袋),已知上下文窗口词(的词袋),预测中心词是什么。
示例代码使用 skip-gram 模型,在每一组训练数据中,X 是中心词,y 是窗口中的上下文(语境)词。
生成训练数据时,需要指定 skip_window,即中心词的左右两侧,每侧的窗口大小。窗口越大,训练数据也就越多。每个中心词两侧窗口共有 2 * skip_window 个词,从中随机取出 num_skips 个。
以 anarchism originated as a term of abuse first used against early working class radicals … 为例,训练数据为 (中心词, 窗口词) = (originated, anarchism), (originated, as), (as, originated), (as, a), (term, a), (term, of), ….
仿照示例,很容易将代码改写为 CBOW 模型。在每一组训练数据中,X是上下文窗口词,y是中心词。这里,只需要指定窗口大小。同样以上述文本和上述窗口大小为例,训练数据为 ([窗口词袋], 中心词) = ([anarchism, as], originated), ([originated, a], as), ([as, term], a), …
事实上,CBOW 模型的输入向量是上下文窗口词的词向量的简单平均。显然这是一种非常简化的模型,但是从结果来看效果也不错。
Step 4 & 5:建立模型并开始训练
用 tensorflow 建立计算模型,两个placeholder用来输入训练数据的 batch 和 labels。
在 embedding 层中,首先对全体词向量随机初始化。示例代码是 skip-gram 模型,每次对训练数据只需用 tf.nn.embedding_lookup() 查表即可。如果改写成 CBOW 模型,那么输入向量是上下文窗口词的词向量的简单平均,因此只需要在前者的基础上增加一步 tf.reduce_mean()。
通常情况下,在类似的模型中,我们的优化原则是 maximum likelyhood (ML)。给定之前的若干个词 ( h ),预测下一个词是 (w_t) 的概率
优化目标是使训练集中的(正)样本的 log-likelihood 最大化,即
但是这样计算代价很高,每一步都需要对所有词计算。
为了提升训练效率,引入负采样(negative sampling)策略,不再用 softmax 对所有词计算概率,而是简化为用 logistic regression 做二元分类。正例是语料中真实的目标词 (w_t),负例是语料中在该窗口没有出现过的 (k) 个其他词 (\tilde w)。从而,优化目标就转化为
这样一来,每一步不再需要计算所有词,而只需要计算选出来的这 (k) 个负例即可。这里使用 tensorflow 自带的 nce_loss() 来近似实现这一策略,它会自动选取负样本。
另外,为了在训练过程中观察效果,随机选取若干个高频词构成验证集,每隔一段时间,列出与它们余弦距离最近的前几个词,观察这些词在语义上与它们是否相近。一开始是随机初始化的,如果训练有效,最终应该会列出它们的近义词(语义功能类似的词)。
下面是采用 skip-gram 模型训练中的部分输出:
Average loss at step 0 : 275.941802979
Nearest to five: nazarbayev, rockers, castello, aiki, kangaroo, bamar, spam, denominated,
Nearest to will: tosefta, piet, butter, anecdote, prelude, uptime, watchmen, patenting,
Average loss at step 10000 : 17.4424968922
Nearest to five: isbn, eight, nine, zero, three, archie, vs, one,
Nearest to will: agave, UNK, butter, officer, prior, aesthetically, die, contacts,
Average loss at step 20000 : 8.1214344871
Nearest to five: nine, eight, zero, three, two, seven, four, six,
Nearest to will: UNK, agave, officer, would, contacts, butter, anecdote, uptime,
Average loss at step 30000 : 5.89534880257
Nearest to five: eight, four, six, zero, seven, nine, three, two,
Nearest to will: would, can, watchmen, agave, tosefta, contacts, officer, disposal,
...
Average loss at step 100000 : 4.71053088367
Nearest to five: four, seven, six, three, eight, two, zero, nine,
Nearest to will: would, can, may, could, must, cannot, should, might,
下面是采用 CBOW 模型训练中的部分输出:
Average loss at step 0 : 308.268066406
Nearest to will: cruiser, nea, intermarried, fooled, harpercollins, warlike, olde, thrones,
Nearest to four: afflicted, alphabetically, merkle, mbox, mattered, bt, contae, digit,
Average loss at step 10000 : 15.2833734883
Nearest to will: done, programming, but, z, meaning, sun, arrives, alabama,
Nearest to four: nine, th, forms, aberdeen, carrel, three, via, japan,
Average loss at step 20000 : 6.8030455755
Nearest to will: would, but, can, familiar, arrives, done, programming, interface,
Nearest to four: nine, six, aberdeen, three, five, th, seven, aim,
Average loss at step 30000 : 5.22375130355
Nearest to will: would, can, but, may, chaplin, cruiser, could, interface,
Nearest to four: six, seven, three, nine, five, two, eight, aberdeen,
...
Average loss at step 100000 : 3.93450297952
Nearest to will: would, can, must, may, might, could, should, cannot,
Nearest to four: six, five, seven, eight, three, nine, two, zero,
Step 6:词向量的可视化
之前对验证集的输出结果,初步展示了模型的训练效果。最后,用t-SNE将词向量降维,绘制在二维平面上,可以看到相似的词有聚集在一起的趋势,这说明 word2vec 的确能够捕捉到语义信息。
对于skip-gram和CBOW两种模型生成的向量,可视化图示如下:
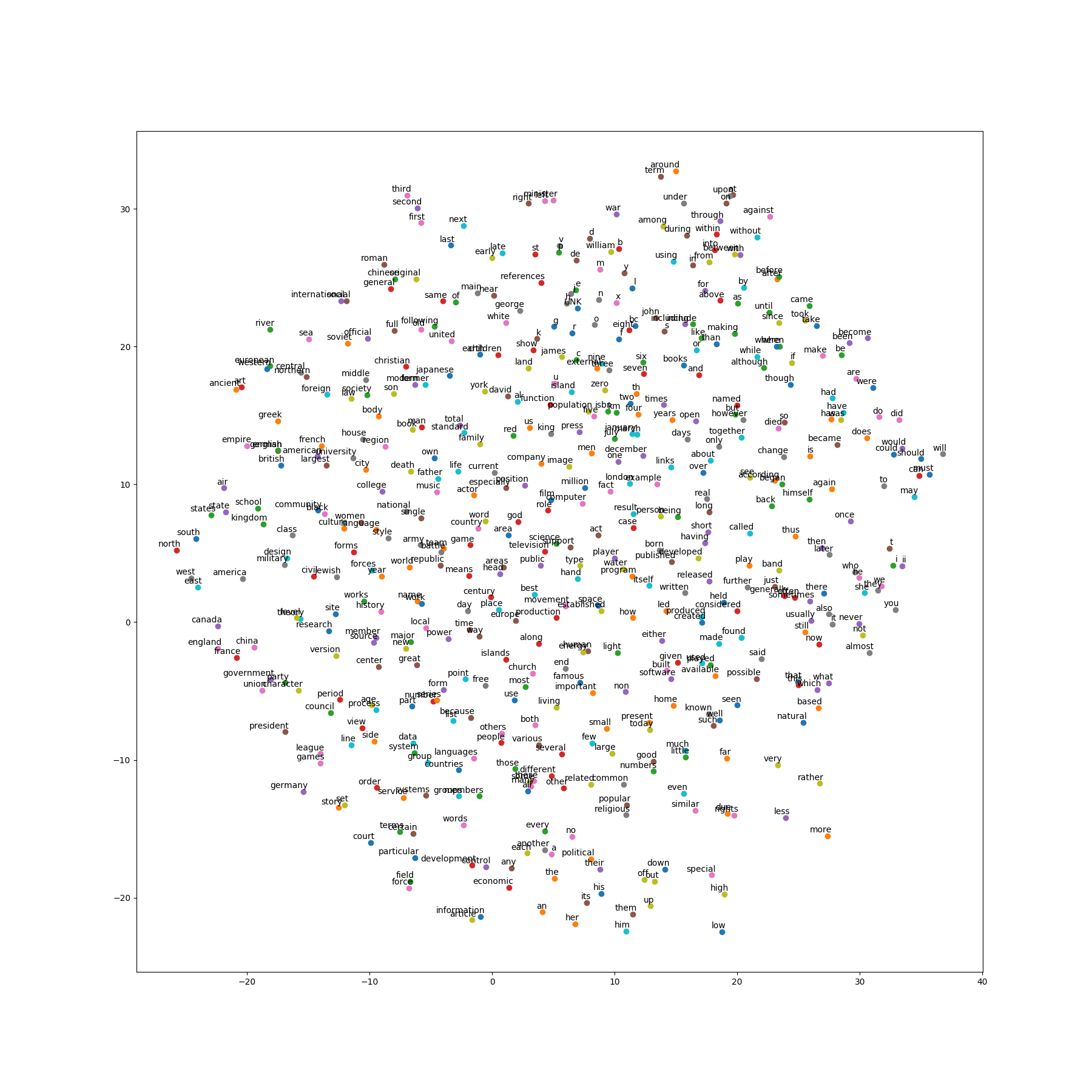
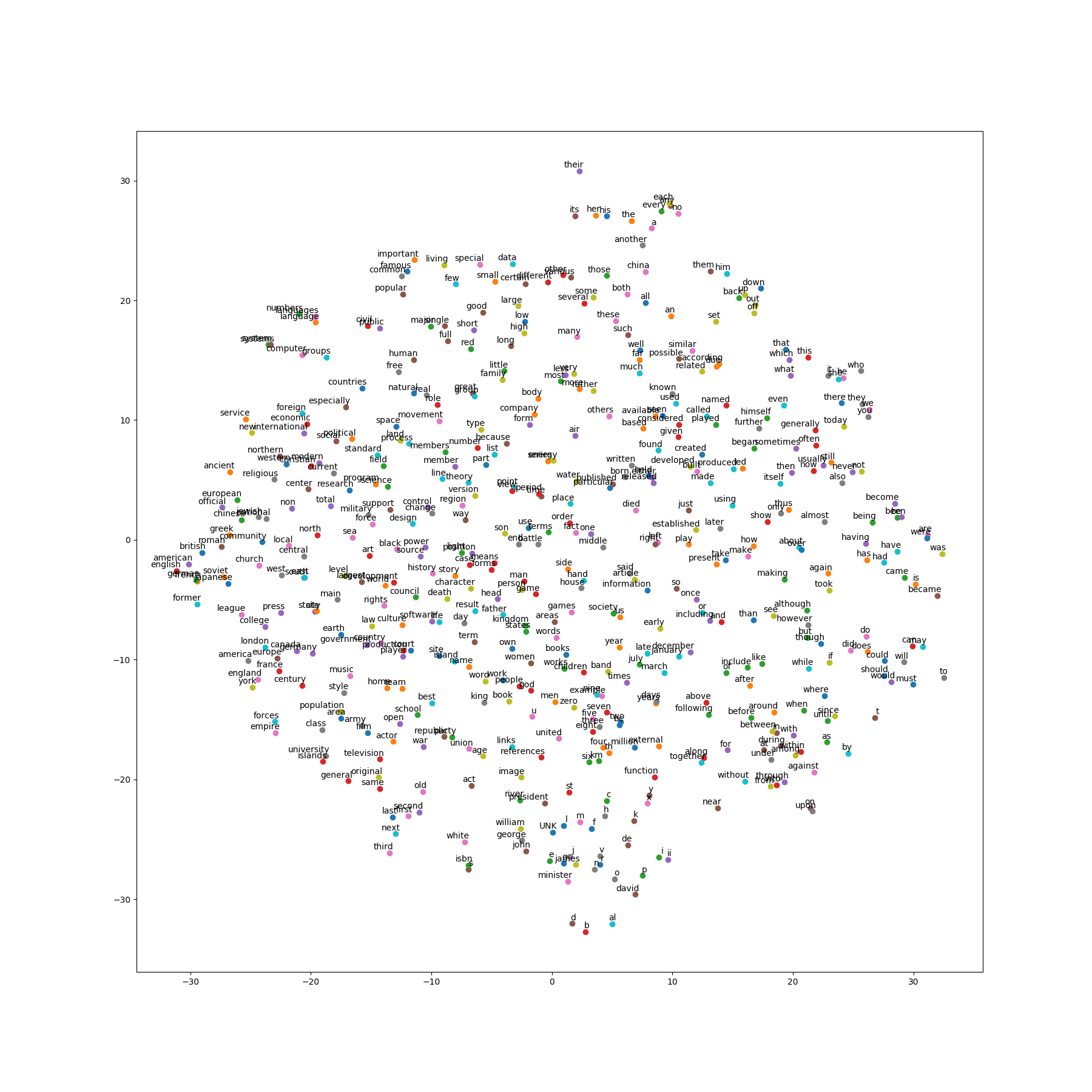
补充
论文还介绍了下采样(sub-sampling)的技巧。在生成训练数据时,如果词频高于给定阈值 (t),则取样概率更低,换句话说,从训练数据中剔除的概率更高, 从而,虽然不改变词频高低顺序,但大幅减少超高频词(如the和of等)的干扰,改善模型对低频词的表达能力。
在原始论文中,每个词都对应两个向量,分别用作输入和输出。按照 CS224N 课程的记号,用 o 表示输出词(索引),c 表示中心词(索引),v 表示输入向量,u 表示输出向量,那么
其中,输入向量就是本文模型中的 embedding 层,也就是本文最终训练得到的向量。关于原理和实现的细节,参见 CS224N 的第一次作业。